Auto-zero/Auto-calibration
From Wikimization
(→Infrared Gas analysers) |
|||
| (51 intermediate revisions not shown.) | |||
| Line 21: | Line 21: | ||
*<math> x\, </math> a collection of some environmental or control variables that need to be estimated | *<math> x\, </math> a collection of some environmental or control variables that need to be estimated | ||
| - | *<math>\bar{x}</math> a | + | *<math>x_c\,</math> a collection of calibration points |
| + | *<math>\bar{x}\,</math> the PDF of <math> x\, </math> . This is a representation of a function. | ||
| + | *<math>\bar{x}(x_c)\,</math> the evaluation of the PDF <math>\bar{x}\,</math> at <math>x_c</math>. | ||
*<math>\hat{x}</math> be the estimate of <math>x\,</math> | *<math>\hat{x}</math> be the estimate of <math>x\,</math> | ||
| - | *<math>p \,</math> a collection of parameters that are constant during operations but selected at design time. The system "real" values during operation are typically <math>p+e \,</math>; although other modifications | + | *<math>p \,</math> a collection of parameters that are constant during operations but selected at design time. The system "real" values during operation are typically <math>p+e \,</math>; although other modifications are possible. |
*<math>e\,</math> be errors: assumed to vary, but constant during intervals between calibrations and real measurements | *<math>e\,</math> be errors: assumed to vary, but constant during intervals between calibrations and real measurements | ||
| + | *<math>\bar{e}\,</math> the PDF of <math> e\, </math> . This is a representation of a function. | ||
| + | *<math>\bar{e}(x)\,</math> the evaluation of the PDF <math>\bar{e}\,</math> at x. | ||
* <math>y\,</math> be the results of a measurement processes attempting to measure <math>x\,</math> | * <math>y\,</math> be the results of a measurement processes attempting to measure <math>x\,</math> | ||
** <math>y=Y(x;p,e)\,</math> where <math>e\,</math> might be additive, multiplicative, or some other form. | ** <math>y=Y(x;p,e)\,</math> where <math>e\,</math> might be additive, multiplicative, or some other form. | ||
| - | ** <math> | + | ** <math>y_c=Y(x_c;p,e)\,</math> the reading values at the calibration points for an instantiation of <math>e\,</math> |
| - | *<math>\hat{e}</math> be estimates of <math>e\,</math> derived from <math> | + | *<math>\hat{e}</math> be estimates of <math>e\,</math> derived from <math>x, y\,</math> |
| - | **<math>\hat{e}= | + | **<math>\hat{e}=Est(x_c,y_c)\,</math> |
*<math>Q(x,\hat{x})</math> be a quality measure of resulting estimation; for example <math>\sum{(x_i-\hat{x_i})^2}</math> | *<math>Q(x,\hat{x})</math> be a quality measure of resulting estimation; for example <math>\sum{(x_i-\hat{x_i})^2}</math> | ||
**Where <math>x\,</math> is allowed to vary over a domain for fixed <math>\hat{x}</math> | **Where <math>x\,</math> is allowed to vary over a domain for fixed <math>\hat{x}</math> | ||
**The example is oversimplified as will be demonstrated below. | **The example is oversimplified as will be demonstrated below. | ||
| - | ** <math>\hat{x} \,</math> is typically decomposed into a chain using <math>\hat{e}</math> | + | ** <math>\hat{x} \,</math> is typically decomposed into a chain using <math>\hat{e}\,</math> |
Then the problem can be formulated as: | Then the problem can be formulated as: | ||
| - | *Given <math> | + | *Given <math>x_c,y_c\,</math> |
| - | *Find a formula or process | + | *Find a formula or process <math>\hat{X}\,</math> to select <math>\hat{X}\left(x_c,y_c\right)\rightarrow\hat{x} \,</math> so as to minimize <math>Q(x,\hat{x})</math> |
** The reason for the process term <math>\hat{X} \,</math> is that many correction schemes are feedback controlled; <math>\hat{X} \,</math> is never computed, internally, although it might be necessary in design or analysis. | ** The reason for the process term <math>\hat{X} \,</math> is that many correction schemes are feedback controlled; <math>\hat{X} \,</math> is never computed, internally, although it might be necessary in design or analysis. | ||
| + | |||
| + | === Algebra of Distributions of Random Variables === | ||
| + | This section discusses algebraic combinations of variables realized from distributions. | ||
| + | * <math>\mathcal{F}(g(x))\,</math> is the Fourier transform of <math>g(x)</math>. | ||
| + | * <math>\mathcal{M}(g(x))\,</math> is the Mellin transform of <math>g(x)</math>. | ||
| + | * <math>\oplus\,</math>:Let | ||
| + | ** <math>c=a+b,\ a,b,c\in \mathbb{R}\,</math>, | ||
| + | ** <math>\overline{c},\overline{a},\overline{b}\,</math> the PDF's of <math>a,b,c \,</math>. | ||
| + | ** <math>\overline{c} = \overline{a}\oplus \overline{b}=\mathcal{F}^{-1}( \mathcal{F}(\overline{a})\cdot \mathcal{F}\left(\overline{b} \right))\,</math> | ||
| + | * <math>\ominus \,</math>:Let | ||
| + | ** <math>c=a-b=a+(-b),\ a,b,c\in \mathbb{R} \,</math>, | ||
| + | ** <math>\overline{c},\overline{a},\overline{b}(-x)\,</math> the PDF's of <math>a,-b,c\,</math>. | ||
| + | ** <math>\overline{c} = \overline{a}\ominus \overline{b}=\mathcal{F}^{-1}( \mathcal{F}(\overline{a})\cdot \mathcal{F}\left(\overline{b}(-x) \right))\,</math> | ||
| + | * <math>\otimes \,</math>:Let | ||
| + | ** <math>c=a\cdot b,\ a,b,c\in (0,\infty)\,</math> | ||
| + | *** Springer as an extension to <math>\mathbb{R} \,</math> | ||
| + | ** <math>\overline{c},\overline{a},\overline{b}\,</math> the PDF's of <math>a,b,c\,</math>. | ||
| + | ** <math>\overline{c} = \overline{a}\otimes \overline{b}=\mathcal{M}^{-1}( \mathcal{M}(\overline{a})\cdot \mathcal{M}\left( \overline{b} \right))\,</math> | ||
| + | * <math>\oslash</math>:Let | ||
| + | ** <math>c= \frac{a}{b},\ a,b,c\in (0,\infty) \,</math> | ||
| + | *** Springer as an extension to <math>\mathbb{R} \,</math> | ||
| + | ** <math>\overline{c},\overline{a},\overline{b}(x)\,</math> the PDF's of <math>a,b,c\,</math>. | ||
| + | ** <math>\overline{c} = \overline{a}\oslash \overline{b}=\mathcal{M}^{-1}( \mathcal{M}(\overline{a})\cdot \mathcal{M}\left(\overline{b}(\frac{1}{x}) \right))\,</math> | ||
| + | Reference: The algebra of random variables, Springer, M.D., 1979, Wiley, New York | ||
== Examples == | == Examples == | ||
| Line 45: | Line 73: | ||
where multiple temperature sensors are multiplexed into a data stream and one or more channels are set aside for Auto-calibration. Expected final systems accuracies of .05 degC are needed because mammalian temperature regulation has resulting in processes and diseases that are "tuned" to particular temperatures. | where multiple temperature sensors are multiplexed into a data stream and one or more channels are set aside for Auto-calibration. Expected final systems accuracies of .05 degC are needed because mammalian temperature regulation has resulting in processes and diseases that are "tuned" to particular temperatures. | ||
* A simplified example, evaluating one calibration channel and one reading channel. In order to be more obvious the unknown and calibration readings are designated separately; instead of the convention given above. This is more obvious in a simple case, but in more complicated cases is unsystematic. | * A simplified example, evaluating one calibration channel and one reading channel. In order to be more obvious the unknown and calibration readings are designated separately; instead of the convention given above. This is more obvious in a simple case, but in more complicated cases is unsystematic. | ||
| - | ** <math>V_x= | + | ** <math>V_x=v_{off}+\frac{V_{ref}R_x}{R_x + R_b}</math> |
** <math>R_x \,</math> can be either the calibration resistor <math>R_c \,</math> or the unknown resistance <math>R_t \,</math> of the thermistor | ** <math>R_x \,</math> can be either the calibration resistor <math>R_c \,</math> or the unknown resistance <math>R_t \,</math> of the thermistor | ||
** <math>V_x \,</math> is the corresponding voltage read: <math>V_c\,</math> or <math>V_t\,</math> | ** <math>V_x \,</math> is the corresponding voltage read: <math>V_c\,</math> or <math>V_t\,</math> | ||
| - | ** <math> | + | ** <math>v_{off} \,</math> is the reading offset value, an error |
| + | ** <math>\overline{v_{off}}\,</math> the PDF of <math>v_{off} \,</math> | ||
** <math>V_{ref}, e_{ref} \,</math> the nominal bias voltage and bias voltage error | ** <math>V_{ref}, e_{ref} \,</math> the nominal bias voltage and bias voltage error | ||
| + | ** <math>\overline{e_{ref}}\, </math> the PDF of <math> e_{ref} \,</math> | ||
** <math>R_b, e_b \,</math> the nominal bias resistor and bias resistor error | ** <math>R_b, e_b \,</math> the nominal bias resistor and bias resistor error | ||
| - | ** <math>e_{com} \,</math> an unknown constant resistance in series with <math>R_c, R_t \,</math> for all readings | + | ** <math>\overline{e_b}\,</math> the PDF of <math>e_b\,</math> |
| + | ** <math>e_{com} \,</math> an unknown constant resistance in series with <math>R_c, R_t \,</math> for all readings | ||
| + | ** <math>\overline{e_{com}}\,</math> the PDF of <math>e_{com} \,</math> | ||
| + | ** <math>\overline{e_{com}'}\,</math> the restricted form of <math>\overline{e_{com}}\,</math> | ||
| + | ***Hereafter <math>x' \,</math> will signify a restricted form of <math>x\,</math> | ||
* With errors | * With errors | ||
| - | ** <math>V_x= | + | ** <math>V_x=v_{off}+\frac{(V_{ref} +e_{ref})(R_x +e_{com})}{(R_x+e_{com} + R_b+e_b)}</math> |
| + | * Implicit formula for PDF distributions. Generally this form two unknown distributions <math>\overline{V_{t}},\overline{R_{t}}\,</math> but in any particular application one or the other is known. In addition the constants, <math>1, V_{ref}, V_b \,</math> in the formula stand for the Dirac delta distribution positioned on the constant. | ||
| + | **<math>\overline{V_{t}}\ominus\overline{v_{off}}\ominus\left(\left(V_{ref}\oplus\overline{e_{ref}}\right)\oslash\left(1\oplus\left(\left(R_{b}\oplus\overline{e_{b}}\right)\oslash\left(\overline{R_{t}}\oplus\overline{e_{com}}\right)\right)\right)\right)=0\,</math> | ||
* Calibration reading | * Calibration reading | ||
** <math>V_c=\left.V_x\right|_{x\leftarrow c}</math> | ** <math>V_c=\left.V_x\right|_{x\leftarrow c}</math> | ||
| Line 61: | Line 97: | ||
* The direct inversion formula illustrates the utility of mathematically using the error space <math>[V_{off}\,,e_{com}\,,e_b\,,e_{ref}] \,</math> during design and analysis. The direct inversion of <math>V_t \,</math> for <math>R_t \,</math> naturally invokes the error space as a link to <math>V_c \,</math>. | * The direct inversion formula illustrates the utility of mathematically using the error space <math>[V_{off}\,,e_{com}\,,e_b\,,e_{ref}] \,</math> during design and analysis. The direct inversion of <math>V_t \,</math> for <math>R_t \,</math> naturally invokes the error space as a link to <math>V_c \,</math>. | ||
** Inversion for <math>R_t \,</math> | ** Inversion for <math>R_t \,</math> | ||
| - | *** <math>R_t=\frac{( | + | *** <math>R_t=\frac{(V_t-v_{off})(e_{com}+R_b+e_b)-e_{com}(V_{ref}+e_{ref})}{V_{ref}-v_{off}-V_t-e_{ref}}</math> |
** Inversion in terms of estimates | ** Inversion in terms of estimates | ||
| - | *** <math>\widehat{R_t}=\frac{(\widehat{ | + | ***<math>\widehat{R_t}=\frac{(V_t-\widehat{v_{off}}) (\widehat{e_{com}}+R_b+\widehat{e_b})-\widehat{e_{com}}(V_{ref}+\widehat{e_{ref}})}{V_{ref}-\widehat{v_{off}}-V_{t}-\widehat{e_{ref}}}</math> |
| - | ** | + | ** Mode estimate: Find the maximum value of <math>\overline{R_{t}'} \,</math>. A necessary condition for differentiable functions is <math>\frac{d\overline{R_{t}'}_{|{p'}}}{dp'}=0 \,</math> In polynomial cases this can theoretically be solved via Groebner basis; but even given the "exact" solutions, one is forced into sub-optimal/approximate estimates. |
| - | + | ** Mean estimate: Find the expectation, that is <math>\widehat{R_t}=\int R'\cdot \overline{R_{t}'}_{|{R'}} dR' </math> | |
| - | ** Mean estimate: | + | |
** Worst case: where points considered where the constraint meets some boundary; say +- .01% | ** Worst case: where points considered where the constraint meets some boundary; say +- .01% | ||
** Any of the above extended to cover a range of <math>R_t \,</math> as well as the range of errors. | ** Any of the above extended to cover a range of <math>R_t \,</math> as well as the range of errors. | ||
| - | * It should be mentioned that, in this case <math>(R_t - \widehat{R_t})</math> is not a good (or natural) function. A better function for both results and calculations is <math>(1-\frac | + | * It should be mentioned that, in this case <math>(R_t - \widehat{R_t})</math> is not a good (or natural) function. A better function for both results and calculations is <math>(1-\frac{\widehat{R_t}}{R_t})\,</math>. The form of errors to be a natural variation from problem to problem and should be accommodated in any organized procedure. |
* Sensitivities are needed during design in order to determine which errors are tight and find out how much improvement can be had by spending more money on individual parts; and during analysis to determine the most likely cause of failures. | * Sensitivities are needed during design in order to determine which errors are tight and find out how much improvement can be had by spending more money on individual parts; and during analysis to determine the most likely cause of failures. | ||
| + | |||
| + | ====Optimization Format==== | ||
| + | *The setpoint case with a full optimzer available at runtime. The purpose is to choose error space values that minimize some likelihood function. The selected error values can then be reused to calculate <math>\widehat{R_t} \,</math> for different values of <math>V_t \,</math>. It is presumed that we choose likelihoods such that surfaces of constant likelihood form a series of nested n-1 dimensional convex sets/shells around a center. | ||
| + | * Absolute value case choosing error values for subsequent calculations. | ||
| + | |||
| + | minimize <math>\frac{|\widehat{v_{off}}|}{L_{off}}\,+\frac{|\widehat{e_{com}}\,-e_{com-center}|}{L_{com}}+\frac{|\widehat{e_{ref}}|}{L_{ref}}\,+\frac{| \widehat{e_b}\,|}{L_b}</math> | ||
| + | |||
| + | w.r.t. <math>\widehat{v_{off}}\,,\widehat{e_{com}}\,,\widehat{e_{ref}}\,,\widehat{e_b}\,</math> | ||
| + | |||
| + | subject to <math>[|\widehat{v_{off}}|\,,\widehat{e_{com}}\,,-\widehat{e_{com}}\,,|\widehat{e_{ref}}|\,,|\widehat{e_b}|]\,\leq\,[L_{off},L_{com},0,L_{ref}\,,L_{b}] | ||
| + | </math><br> | ||
| + | <math>V_c=\widehat{v_{off}}+\frac{(V_{ref} +\widehat{e_{ref}})(R_c +\widehat{e_{com}})}{(R_c+\widehat{e_{com}} + R_b+\widehat{e_b})} | ||
| + | </math> | ||
| + | |||
| + | ====Optimization Format 2==== | ||
| + | * Reformulation in extended matrix format. A derivation is in the [[Talk:Auto-zero/Auto-calibration | discussion]] under /* Optimization Format */. | ||
| + | * We introduce a new variable to produce coupled equations: <math>\widehat{I_c}\,</math>. This is meant to simplify the nonlinearities. | ||
| + | |||
| + | minimize <math>\frac{|\widehat{v_{off}}|}{L_{off}}\,+\frac{|\widehat{e_{com}}\,-e_{com-center}|}{L_{com}}+\frac{|\widehat{e_{ref}}|}{L_{ref}}\,+\frac{| \widehat{e_b}\,|}{L_b}</math> | ||
| + | |||
| + | w.r.t. <math>\widehat{v_{off}}\,,\widehat{e_{com}}\,,\widehat{e_{ref}}\,,\widehat{e_b}\,,\widehat{I_c} | ||
| + | </math> | ||
| + | |||
| + | subject to <math>[|\widehat{v_{off}}|\,,\widehat{e_{com}}\,,-\widehat{e_{com}}\,,|\widehat{e_{ref}}|\,,|\widehat{e_b}|]\,\leq\,[L_{off}\,,L_{com}\,,0,L_{ref}\,,L_{b}] | ||
| + | </math><br> | ||
| + | <math>\begin{array}{lcl} | ||
| + | \left[\begin{array}{c} | ||
| + | V_{ref}\\ | ||
| + | V_{c}\end{array}\right] & = & \left[\begin{array}{ccccc} | ||
| + | 1 & (R_{b}+R_{c}) & 1 & 1 & 0\\ | ||
| + | 0 & R_{c} & 0 & 1 & 1\end{array}\right]\left[\begin{array}{c} | ||
| + | \widehat{e_{ref}}\\ | ||
| + | \widehat{I_{c}}\\ | ||
| + | \widehat{I_{c}}\,\widehat{e_{b}}\\ | ||
| + | \widehat{I_{c}}\,\widehat{e_{com}}\\ | ||
| + | \widehat{v_{off}}\end{array}\right]\end{array} | ||
| + | </math> | ||
| + | <math>\begin{array}{lcl} | ||
| + | |\widehat{e_{ref}}| & < & V_{ref}\\ | ||
| + | \widehat{I_{c}} & > & 0\\ | ||
| + | V_{c} & < & V_{ref}+\widehat{e_{ref}}\end{array} | ||
| + | </math> | ||
| + | |||
| + | ====Optimization Format 3==== | ||
| + | *Working directly on choosing the most likely value of <math>\widehat{R_{t}}</math>. | ||
| + | |||
| + | minimize r | ||
| + | |||
| + | w.r.t <math>\widehat{R_{t}}\,</math> | ||
| + | <math>\widehat{v_{off}}\,,\widehat{e_{com}}\,,\widehat{e_{ref}}\,,\widehat{e_b}\,</math> | ||
| + | |||
| + | |||
| + | subject to | ||
| + | <math>V_c=\widehat{v_{off}}+\frac{(V_{ref} +\widehat{e_{ref}})(R_c +\widehat{e_{com}})}{(R_c+\widehat{e_{com}} + R_b+\widehat{e_b})} | ||
| + | </math> | ||
| + | <math>V_t=\widehat{v_{off}}+\frac{(V_{ref} +\widehat{e_{ref}})(\widehat{R_t} +\widehat{e_{com}})}{(\widehat{R_t}+\widehat{e_{com}} + R_b+\widehat{e_b})} | ||
| + | </math> | ||
| + | <math>\left(\frac{{\widehat{v_{off}}-\mu_{off}}}{\sigma_{off}}\right)^2+\left(\frac{{\widehat{e_{com}}-\mu_{com}}}{\sigma_{com}}\right)^2+\left(\frac{{\widehat{e_{ref}}-\mu_{ref}}}{\sigma_{ref}}\right)^2+\left(\frac{{\widehat{e_{b}}-\mu_{b}}}{\sigma_{b}}\right)^2 =r | ||
| + | </math> | ||
| + | <math>\widehat{R_{t}} > 0</math> | ||
| + | |||
| + | ====Optimization Format 4==== | ||
| + | *An alternate selection criteria; probably not usable. | ||
| + | |||
| + | minimize r | ||
| + | |||
| + | w.r.t <math>\bold{E}(\widehat{R_{t}})\,</math> | ||
| + | <math>\widehat{v_{off}}\,,\widehat{e_{com}}\,,\widehat{e_{ref}}\,,\widehat{e_b}\,</math> | ||
| + | |||
| + | |||
| + | subject to | ||
| + | <math>V_c=\widehat{v_{off}}+\frac{(V_{ref} +\widehat{e_{ref}})(R_c +\widehat{e_{com}})}{(R_c+\widehat{e_{com}} + R_b+\widehat{e_b})} | ||
| + | </math> | ||
| + | <math>V_t=\widehat{v_{off}}+\frac{(V_{ref} +\widehat{e_{ref}})(\widehat{R_t} +\widehat{e_{com}})}{(\widehat{R_t}+\widehat{e_{com}} + R_b+\widehat{e_b})} | ||
| + | </math> | ||
| + | <math>\left(\frac{{\widehat{v_{off}}-\mu_{off}}}{\sigma_{off}}\right)^2+\left(\frac{{\widehat{e_{com}}-\mu_{com}}}{\sigma_{com}}\right)^2+\left(\frac{{\widehat{e_{ref}}-\mu_{ref}}}{\sigma_{ref}}\right)^2+\left(\frac{{\widehat{e_{b}}-\mu_{b}}}{\sigma_{b}}\right)^2 =r | ||
| + | </math> | ||
| + | <math>\widehat{R_{t}} > 0</math> | ||
===Infrared Gas analysers=== | ===Infrared Gas analysers=== | ||
Current revision
Contents |
Motivation
In instrumentation, both in a supporting role and as a prime objective, measurements are taken that are subject to systematic errors. Routes to minimizing the effects of these errors are:
- Spend more money on the hardware. This is valid but hits areas of diminishing returns; the price rises disproportionately with respect to increased accuracy.
- Apparently, in the industrial processing industry, various measurement points are implemented and regressed to find "subspaces" that the process has to be operating on. Due to lack of experience I (RR) will not be covering that here; although others are welcome to (and replace this statement). This is apparently called "data reconciliation".
- Calibrations are done and incorporated into the instrument. This can be done by analog adjustments or written into storage mediums for subsequent use by operators or software.
- Runtime Auto-calibrations done at regular intervals. These are done at a variety of time intervals: every .01 seconds to 30 minutes. I can speak to these most directly; but I consider the "Calibrations" to be a special case.
Mathematical Formulation
Nomenclature:
It will be presumed, unless otherwise stated, that collected variables compose a (topological) manifold; i.e. a collection designated by single symbol and id. Not necessarily possessing a differential geometry metric. The means that there is no intrinsic two dimensional tensor, , allowing a identification of contravarient vectors with covarient ones. These terms are presented to provide a mathematically precise context to distinguish: contravarient and covariant vectors, tangent spaces and underlying coordinate spaces. Typically they can be ignored.
- The quintessential example of covariant tensor is the differential of a scaler, although the vector space formed by differentials is more extensive than differentials of scalars.
- The quintessental contravariant vector is the derivative of a path
with component values
on the manifold. With
being a component of the contravariant vector along
- Using
(see directly below) as an example
-
refers to collection of variables identified by "id"
- Although a collection does not have the properties of a vector space; in some cases we will assume (restrict) it have those properties. In particular this seems to be needed to state that the Q() functions are convex.
-
refers to the
component of
-
refers to the tangent/cotangent bundle with
selecting a contravariant component and
selecting a covariant component
-
refers to an expression, "expr", where
is evaluated with
-
refers to an expression, "expr", where
-
Definitions:
a collection of some environmental or control variables that need to be estimated
a collection of calibration points
the PDF of
the evaluation of the PDF
.
be the estimate of
; although other modifications are possible.
be errors: assumed to vary, but constant during intervals between calibrations and real measurements
the PDF of
. This is a representation of a function.
the evaluation of the PDF
-
be the results of a measurement processes attempting to measure
-
where
-
the reading values at the calibration points for an instantiation of
-
be estimates of
be a quality measure of resulting estimation; for example
- Where
is allowed to vary over a domain for fixed
- The example is oversimplified as will be demonstrated below.
-
is typically decomposed into a chain using
- Where
Then the problem can be formulated as:
- Given
- Find a formula or process
to select
so as to minimize
- The reason for the process term
is that many correction schemes are feedback controlled;
- The reason for the process term
Algebra of Distributions of Random Variables
This section discusses algebraic combinations of variables realized from distributions.
-
is the Fourier transform of
.
-
is the Mellin transform of
-
:Let
-
,
-
the PDF's of
.
-
-
-
:Let
-
,
-
the PDF's of
.
-
-
-
:Let
-
- Springer as an extension to
- Springer as an extension to
-
.
-
-
-
:Let
-
- Springer as an extension to
- Springer as an extension to
-
the PDF's of
-
-
Reference: The algebra of random variables, Springer, M.D., 1979, Wiley, New York
Examples
Biochemical temperature control
where multiple temperature sensors are multiplexed into a data stream and one or more channels are set aside for Auto-calibration. Expected final systems accuracies of .05 degC are needed because mammalian temperature regulation has resulting in processes and diseases that are "tuned" to particular temperatures.
- A simplified example, evaluating one calibration channel and one reading channel. In order to be more obvious the unknown and calibration readings are designated separately; instead of the convention given above. This is more obvious in a simple case, but in more complicated cases is unsystematic.
-
-
can be either the calibration resistor
or the unknown resistance
of the thermistor
-
is the corresponding voltage read:
or
-
is the reading offset value, an error
-
the PDF of
-
the nominal bias voltage and bias voltage error
-
the PDF of
-
the nominal bias resistor and bias resistor error
-
the PDF of
-
an unknown constant resistance in series with
for all readings
-
the PDF of
-
the restricted form of
- Hereafter
will signify a restricted form of
- Hereafter
-
- With errors
-
- Implicit formula for PDF distributions. Generally this form two unknown distributions
but in any particular application one or the other is known. In addition the constants,
in the formula stand for the Dirac delta distribution positioned on the constant.
- Calibration reading
-
- Thermistor (real) reading
-
- The problem is to optimally estimate
based upon
and
- The direct inversion formula illustrates the utility of mathematically using the error space
during design and analysis. The direct inversion of
.
- Inversion for
-
- Inversion in terms of estimates
- Mode estimate: Find the maximum value of
. A necessary condition for differentiable functions is
In polynomial cases this can theoretically be solved via Groebner basis; but even given the "exact" solutions, one is forced into sub-optimal/approximate estimates.
- Mean estimate: Find the expectation, that is
- Worst case: where points considered where the constraint meets some boundary; say +- .01%
- Any of the above extended to cover a range of
- Inversion for
- It should be mentioned that, in this case
is not a good (or natural) function. A better function for both results and calculations is
. The form of errors to be a natural variation from problem to problem and should be accommodated in any organized procedure.
- Sensitivities are needed during design in order to determine which errors are tight and find out how much improvement can be had by spending more money on individual parts; and during analysis to determine the most likely cause of failures.
Optimization Format
- The setpoint case with a full optimzer available at runtime. The purpose is to choose error space values that minimize some likelihood function. The selected error values can then be reused to calculate
for different values of
- Absolute value case choosing error values for subsequent calculations.
minimizew.r.t.
subject to

Optimization Format 2
- Reformulation in extended matrix format. A derivation is in the discussion under /* Optimization Format */.
- We introduce a new variable to produce coupled equations:
. This is meant to simplify the nonlinearities.
minimizesubject to
![LaTeX: \begin{array}{lcl}
</pre>
<p>\left[\begin{array}{c}
V_{ref}\\
V_{c}\end{array}\right] & = & \left[\begin{array}{ccccc}
1 & (R_{b}+R_{c}) & 1 & 1 & 0\\
0 & R_{c} & 0 & 1 & 1\end{array}\right]\left[\begin{array}{c}
\widehat{e_{ref}}\\
\widehat{I_{c}}\\
\widehat{I_{c}}\,\widehat{e_{b}}\\
\widehat{I_{c}}\,\widehat{e_{com}}\\
\widehat{v_{off}}\end{array}\right]\end{array}
</p>
<pre>](http://convexoptimization.com/wikimization/cgi-bin/mimetex.cgi?%5Cbegin%7Barray%7D%7Blcl%7D%0A%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D%0AV_%7Bref%7D%5C%5C%0AV_%7Bc%7D%5Cend%7Barray%7D%5Cright%5D%20%26%20%3D%20%26%20%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D%0A1%20%26%20%28R_%7Bb%7D%2BR_%7Bc%7D%29%20%26%201%20%26%201%20%26%200%5C%5C%0A0%20%26%20R_%7Bc%7D%20%26%200%20%26%201%20%26%201%5Cend%7Barray%7D%5Cright%5D%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D%0A%5Cwidehat%7Be_%7Bref%7D%7D%5C%5C%0A%5Cwidehat%7BI_%7Bc%7D%7D%5C%5C%0A%5Cwidehat%7BI_%7Bc%7D%7D%5C%2C%5Cwidehat%7Be_%7Bb%7D%7D%5C%5C%0A%5Cwidehat%7BI_%7Bc%7D%7D%5C%2C%5Cwidehat%7Be_%7Bcom%7D%7D%5C%5C%0A%5Cwidehat%7Bv_%7Boff%7D%7D%5Cend%7Barray%7D%5Cright%5D%5Cend%7Barray%7D%0A%20%20%20%20%20%20%20%20%20%20%20)

Optimization Format 3
- Working directly on choosing the most likely value of
.
minimize r w.r.t


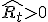
Optimization Format 4
- An alternate selection criteria; probably not usable.
minimize r w.r.t
Infrared Gas analysers
With either multiple stationary filters or a rotating filter wheel. In either case the components, sensors, and physical structures are subject to significant variation.
Various forms of 
- Weighted least squares of
- Minimize mode of
- Minimize the mean of
- Minimize the worst case of
- Some weighting of the error interval with respect to
Areas of optimization
Design
Runtime
Calibration usage